Schedule
以下是推荐的作业安排,每周的任务是一个大致的估计,具体的时间可能会有所调整。
| Weeks | Tasks | Reading |
|---|---|---|
| 第二周 | 选大作业/小作业 | rCore 第零章 |
| 第三周-第四周 | 基于 SBI 写 hello world | rCore 第一章 |
| 第五周-第七周 | 页表和特权级转化 (m-mode -> s-mode),实现 buddy allocator | rCore 第二章、第四章 |
| 第八周-第九周 | 创建单进程(s-mode -> u-mode)和 trap | rCore第五章 |
| 第十周-第十二周 | process manager,scheduler | rCore 第三章 |
| 第十三周-第十六周 | drivers, FS,shell | rCore 第六章、第九章 |
| 第十七周 | IPC | rCore 第七章 |
注意:本文档不能代替 RISCV64 特权指令集文档,如对 RISCV 特权指令集相关内容有不清楚的地方,请参阅 RISCV 特权指令集文档。
帮助
本章节将会提供一些编写内核过程中的帮助,譬如 GDB 的使用指南、特权寄存器指南等。
GDB 操作指南
基础 GDB 命令及示例
不出意外的话,当你们执行 GDB 时将会看到以下内容:
GNU gdb (GDB) 13.2
Copyright (C) 2023 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/g
pl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "--host=x86_64-pc-linux-gnu --target=riscv
64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
--Type <RET> for more, q to quit, c to continue without paging--
cumentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word".
Reading symbols from target/riscv64gc-unknown-none-elf/release/kernel
...
The target architecture is set to "riscv:rv64".
Remote debugging using localhost:1234
0x0000000000001000 in ?? ()
(gdb)
Help
所有指令都可以查看 GDB 的帮助文档,只需要在 GDB 中输入 help command 即可。例如
(gdb) help x
其显示:
Examine memory: x/FMT ADDRESS.
ADDRESS is an expression for the memory address to examine.
FMT is a repeat count followed by a format letter and a size letter.
Format letters are o(octal), x(hex), d(decimal), u(unsigned decimal), t(binary), f(float), a(address), i(instruction), c(char), s(string) and z(hex, zero padded on the left).
Size letters are b(byte), h(halfword), w(word), g(giant, 8 bytes).
The specified number of objects of the specified size are printed according to the format. If a negative number is specified, memory is examined backward from the address.
Defaults for format and size letters are those previously used.
Default count is 1. Default address is following last thing printed
with this command or "print".
查看 Assembly 与 Memory
首可以通过 layout asm 来查看汇编代码,其会将 GDB 的窗口分为上下两部分,上部分显示汇编代码,下部分是调试窗口。
当然,你也可以通过 examine memory 来查看任意地址的汇编代码,例如:
(gdb) x/10i 0x1000
这个命令会展示地址 0x1000 开始的 10 条汇编指令。其中,10 代表展示的指令数量,i 代表展示的格式。支持的格式可以在 help x 中查看。
同样的,你可以利用 x 来查看内存,例如:
(gdb) x/10x 0x8001c0a0
这个命令会展示地址 0x8001c0a0 开始的 10 个 4 字节的内存单元。
设置断点
利用地址设置断点
我们一开始进入 QEMU 的地址是 0x1000,我们可以在 0x80000000 处设置断点,方便调试,例如:
b *0x80000000
Breakpoint 1 at 0x80000000: file src/main.rs, line 67.
注意,这里的 b 是 break 的缩写。
* 表示后面值是一个 address 而不是一个 symbol,因为我们也可以利用 symbol 来设置断点。
利用符号设置断点
我们可以利用符号来设置断点。我们以 recore 中的 entry point 为例:
b _start
Breakpoint 2 at 0x80000000: file src/main.rs, line 67.
便可以在 _start 这个函数的入口处设置断点,但需要注意的是,由于 Rust 的函数名会被 mangle,所以我们需要在函数名前加上 #[no_mangle] 来防止编译器修改函数名,例如:
#[no_mangle]
unsafe extern "C" fn _start() {
todo!()
}
#[no_mangle]
fn foo() {
todo!()
}
#[no_mangle]
unsafe fn bar() {
todo!()
}一般来说,只有加上 #[no_mangle] 的函数名才能在 GDB 中被识别,可以通过 info address 来查看 symbol 的地址,例如:
(gdb) info address _start
Symbol "_start" is at 0x80000000 in a file compiled without debugging.
同理,我们可以在 GDB 中找到 foo 和 bar 这两个 symbol,并设置断点。
利用文件名和行号设置断点
我们也可以利用文件名和行号来设置断点,假设我们的根目录下有一个文件 src/main.rs,我们可以利用 b src/main.rs:67 来设置断点于此处:
66 unsafe extern "C" fn _start() {
67 asm!(
68 "la sp, {bootloader_stack}",
69 "li t0, {bootloader_stack_size}",
70 "csrr t1, mhartid",
71 "addi t1, t1, 1",
72 "mul t0, t0, t1",
73 "add sp, sp, t0",
74 "j {rust_start}",
75 bootloader_stack = sym BOOTLOADER_STACK_SPACE,
76 bootloader_stack_size = const BOOTLOADER_STACK_SIZE,
77 rust_start = sym rust_start,
78 options(noreturn),
79 );
80 }只需要:
(gdb) b src/main.rs:67
Breakpoint 3 at 0x80000000: file src/main.rs, line 67.
再举一个例子,例如在87行处设置断点(这个函数不需要 #[no_mangle]:
85 unsafe fn rust_start() -> ! {
86 mstatus::set_mpp(riscv::register::mstatus::MPP::Supervisor);
87 mepc::write(rust_main as usize);
88 todo!("...")
89 }(gdb) b src/main.rs:88
Breakpoint 4 at 0x8001c0cc: file src/main.rs, line 88.
逐行执行
利用 si 或者 ni 逐行执行代码:
(gdb) si
(gdb) ni
当程序停在某个断点时,使用此命令可以一行行地跟踪程序执行流程,包括进入函数体内部。
打印寄存器
p 可以查看某个寄存器当前的值:
(gdb) p $pc
将 $pc 换成你想要查看的寄存器即可。
打印变量
p 可以打印某个变量的值。譬如说,我想打印180行处的 hart_id:
fn init_devices() {
let hart_id = Processor::hart_id();
...
}当执行完 b src/main.rs:180 后,我们可以打印 hart_id 的值:
(gdb) print hart_id
同时,我们可以利用 info locals 来显示所有可供打印的所有局部变量。
执行到断点
c 或 continue 从当前停止点继续执行程序,直到遇到下一个断点或程序结束:
(gdb) c
特权寄存器指南
本文档将介绍如何方便地修改和读取特权寄存器,以及修改和读取特权寄存器的特定字段。
rCore 的 riscv 库提供了较为全面的特权寄存器支持。利用这个库,我们可以更方便地操作特权寄存器。
导入 riscv 库
首先,在 Cargo.toml 的 [dependencies] 中加一行
riscv = { git = "https://github.com/rcore-os/riscv", features = ["inline-asm"] }
然后在需要使用 riscv 库的文件中 use riscv::register::<reg>; 即可使用对应的寄存器。如果使用的寄存器较多,也可以 use riscv::register::*; 导入所有的寄存器。
修改特权寄存器
我们可以使用寄存器的 write 方法来写入特权寄存器。
例如我们需要将 mepc 设置为 main 函数(这个操作在从 m mode 到 s mode 中很重要,函数名可以不同),我们可以(需要在函数中调用 write)
use riscv::register::mepc;
...
mepc::write(rust_main as usize);读取特权寄存器
我们可以使用寄存器的 read 方法来读取特权寄存器。
例如我们需要读取 sstatus,我们可以
use riscv::register::sstatus;
...
let sstatus = sstatus::read();修改寄存器的特定字段
我们可以使用寄存器的 set_<name> 方法来修改特定字段。
例如我们需要修改 mstatus 的 MPP 位,我们可以
use riscv::register::mstatus;
...
mstatus::set_mpp(riscv::register::mstatus::MPP::Supervisor);读取寄存器的特定字段
我们可以使用寄存器的 <name> 方法来读取特定字段。
例如我们需要读取 mstatus 的 MPP 位,我们可以
use riscv::register::mstatus;
...
let mpp = mstatus::mpp();RISCV 汇编编写贴士
切换页表
在切换页表时,为了防止出现不一致的情况,我们需要先清空 TLB(这个过程保证了旧的页表的数据是正确的),然后切换页表,之后再清空 TLB。
在 RISCV 中,我们可以通过 sfence.vma 指令来清空 TLB。
比如在切换页表时,我们可以这样做:(假设 t0 是新的 satp)
# clear TLB
sfence.vma
# switch page table
csrw satp, t0
# clear TLB
sfence.vma
利用 scratch 储存临时变量
在编写一些代码时(尤其是 trap vectors),我们需要使用除了通用寄存器之外的寄存器储存临时变量。比如将所有的通用寄存器保存到特定内存地址时,我们还需要寄存器储存内存地址。我们可以利用 RISCV 中的 mscratch/sscratch 寄存器来储存这些临时变量。
通常情况下,我们会先将一个寄存器的值储存在 scratch 上,然后完成操作后,再还原这个寄存器的值。
比如当我们需要将所有通用寄存器储存到 TRAP_CONTEXT 开始的地址时,我们可以:
# save user a0 in sscratch so a0 can be used to get at TRAP_CONTEXT.
csrw sscratch, a0
li a0, TRAP_CONTEXT
# save the user registers except a0 in TRAP_CONTEXT
...
...
# save previous a0 to TRAP_CONTEXT
csrr t0, sscratch
sd t0, 112(a0)
Rust 项目的 Cargo 包布局教程
当您使用 Rust 进行项目开发时,有效的文件结构组织对于项目管理和可维护性至关重要。Cargo —— Rust 的包管理器和构建工具,定义了一套文件放置的约定来简化了解新 Cargo 包的过程。以下是如何根据这些约定来组织您的 Rust 项目的教程。
基本文件结构
Cargo 包的典型目录结构如下所示:
.
├── Cargo.lock
├── Cargo.toml
├── src/
│ ├── lib.rs
│ ├── main.rs
│ └── bin/
│ ├── named-executable.rs
│ ├── another-executable.rs
│ └── multi-file-executable/
│ ├── main.rs
│ └── some_module.rs
├── benches/
│ ├── large-input.rs
│ └── multi-file-bench/
│ ├── main.rs
│ └── bench_module.rs
├── examples/
│ ├── simple.rs
│ └── multi-file-example/
│ ├── main.rs
│ └── ex_module.rs
└── tests/
├── some-integration-tests.rs
└── multi-file-test/
├── main.rs
└── test_module.rs
- Cargo.toml 和 Cargo.lock:这两个文件存储在包的根目录(package root),包含项目的基本信息和一些 dependencies。
- src 目录:源代码放在这里,其中
src/lib.rs是默认的库文件,src/main.rs是默认的执行文件。- 其他执行文件可以放在
src/bin/目录下。
- 其他执行文件可以放在
- benches 目录:用于存放基准测试文件,以测试代码性能。
- examples 目录:里面放的是示例代码,通常展示如何使用库。
- tests 目录:用于集成测试文件,检查不同模块是否正常协作。
Cargo Build
How To Use
当你运行 cargo build 命令时,Cargo 会自动寻找项目中所有的可编译资源,包括 lib.rs、main.rs 以及 bin/ 目录下的每个 .rs 文件。每个源码文件都会被编译成独立的二进制可执行文件。
- 编译整个项目:简单运行
cargo build会构建项目中的所有可执行文件和库。 - 编译特定的二进制文件:如果你只想编译
bin/目录中的特定文件,可以使用cargo build --bin <name>。
What Happened?
考虑一次 cargo build 的过程:
- 解析依赖:Cargo 首先读取
Cargo.toml文件,解析项目依赖。 - 编译库:如果存在
lib.rs,Cargo 会首先编译库。 - 编译二进制应用:随后,Cargo 编译
src/main.rs(如果存在)和bin/目录下的所有文件,为每个文件生成一个可执行文件。 - 放置可执行文件:编译成功后,可执行文件将被放置在
target/debug/目录下,文件名与bin/目录中的源文件名相匹配。
操作系统简介
我们为什么需要操作系统?
最早的计算机是没有操作系统的,程序以独占的方式运行于硬件之上。
然而,当我们希望在一个硬件上运行多个程序时,资源的分配成了一个大问题。如对于内存资源,程序之间无法协商使用的内存,如果两个程序同时使用同一块内存,那么两个程序都很可能会发生错误。
因此,一个可以统一管理各种资源的程序是相当重要的。这个程序就是我们现在所说的操作系统。
操作系统功能
需要注意的是,操作系统本质上就是一个程序,在本质上和其他程序没有区别。操作系统不是魔法,所有的功能都是利用了硬件特性结合软件工程实现的。
下面我们会对一些核心的功能进行简单介绍。
用户态/内核态
你可能会问,虽然说操作系统本质上就是一个程序,那么其他程序怎么不能成为操作系统呢?如果其他程序能成为操作系统,那么操作系统的资源管理不就无法完成了吗?
实际上,一个程序是否能成为操作系统,取决于其所在的特权状态。如果没有特权,那么这个程序就是普通的用户态程序。
特权状态及其转移是通过硬件(或者模拟硬件的软件)实现的。也就是说,硬件维护了一个特权状态,并且提供了一些切换特权的方式。
从高特权级到低特权级是可以很轻易完成的,因为这个操作中权限是严格变小的。反过来,从低特权级到高特权级的操作也是经常发生的。这可能有一些反直觉,为什么可以从低特权级别转到高特权级别呢?要回答这个问题,我们需要思考为什么需要从低特权切换到高特权。注意到当我们主动地需要操作系统做一些事情1时,那么我们就是需要从低特权的用户程序进入到高特权的内核。为了防止出现低特权级别程序获得高特权后做一些破坏性的事情,我们会限制切换特权级后 PC 的值。
这被称为 system call,即系统调用。
在 RISCV 中,一共有 4 个特权等级,从高到低分别是 machine mode、hypervisor mode(给虚拟机预留,我们内核用不到)、supervisor mode 和 user mode。
Machine mode 负责处理一些非常底层的工作,比如 timer interrupt。
Supervisor mode 即为内核所在的特权级,会完成内核绝大多数的工作。
User mode 为用户程序所在的特权级。
RISCV 根据不同的需求,设计了一套同步和一套异步的切换机制,具体参见陷入 (Trap)、中断 (Interrupt) 与异常 (Exception) 介绍。
内存管理
内存管理是内核中很重要的一个功能。
管理用户态程序的方法是使用虚拟内存。虚拟内存地址空间由页表控制,可以控制每个页面的访问权限(读/写/执行),以及其他控制权限。页表由内核控制。
除了管理用户态程序的地址空间,内核还需要处理内存的分配。内存分配对象是内核以及所有用户态程序。内核需要负责分配和回收内存。
进程管理
进程是资源管理的基本单位。内核中需要管理好每个程序使用的资源。
外部设备管理
除了上面的哪些功能,内核还需要管理硬件,并为用户态程序做好设备的抽象,方便设备的使用。
操作系统流程
一个操作系统从入口点开始大致需要做下面的几个事情:
- 设置正确的环境(包括中断等);
- 进入内核所在的特权级;
- 进行内核组建的初始化;
- 运行第一个应用程序;
- 为所有的应用程序服务,并对应用程序进行合理的调度。
陷入 (Trap)、中断 (Interrupt) 与异常 (Exception)
前面的操作系统介绍中,我们知道 RISCV 根据不同的需求,设计了一套同步和一套异步的特权级切换机制。这里我们会解释一下这两种切换机制(但不会对具体细节进行过多地阐释,具体细节会在后面的文档中慢慢介绍)。
注:陷入、中断、异常三个概念在不同的地方有不同的含义。我们这里只是在 RISCV 语境下的含义。
中断 (Interrupt) 是异步的特权级切换机制,绝大多数情况下与 CPU 当前指令的执行无关。发生中断时,CPU 会停止当前指令的执行,转到指定的处理指令处,开始执行处理函数。中断可以被暂时关闭,关闭时 CPU 不会停止当前指令的执行。
异常 (Exception) 是同步的特权级切换机制,与 CPU 当前指令的执行有关。异常可以是主动发起的,也可以是访问了非法地址等错误导致的,或者是碰到了之前设置的断点而触发的。异常是无法被关闭的,一旦发生,就一定会跳转到指定的异常处理指令,开始自行处理函数。
陷入 (Trap) 是指异常和中断的统称。
不同机制的应用场景
当我们的应用需要向内核申请使用某种未获得资源时,就需要主动地发起一次进入内核的请求,这个过程通常是同步的,也就是我们说的「异常」。
不过,当我们想要在特定时间点切换运行的任务时,我们不能让应用主动在特定的时间交出运行的权利,因为应用如果不交出,其可以一直占用 CPU。这时,我们需要使用异步的时钟中断机制。时钟中断机制会在硬件层面打破应用的运行(用户态是无法关闭中断的),并将控制权交给内核。
上面的两个例子分别是「异常」和「中断」的应用场景。
内核基本环境
和其他的应用一样,内核也需要一些基本的环境才能运行。
不过,与其他应用不同的是,在运行其他应用时,操作系统做了很多工作,因此很多基本的环境都是现成的,而对于内核来说,几乎所有的环境都需要自己来创造。
具体来说,当内核被引导时,我们唯一可以确定的通用寄存器是 pc,包括 sp 在内的其他可写通用寄存器是没有意义的。也就是说,我们甚至没有函数栈。因此,在执行到内核的第一条指令时,我们无法使用任何常规的高级语言,必须使用机器码或者汇编。并利用这些代码设置函数栈。具体请见内核入口部分。
接下来,我们还需要一些处理与硬件相关的支持,具体请见 Supervisor Binary Interface (SBI) 介绍。
然后,我们需要处理特权级机制相关的部分,从 m mode 进入 s mode。
进入 supervisor mode 之后,我们需要初始化内存分配器,为内核的页面分配提供服务。
接着,我们需要设置内核的页表。关于 RISCV 下的 SV39 页表机制,请见页表介绍。
内核入口
我们知道,当内核被引导时,我们唯一可以确定的通用寄存器是 pc,包括 sp 在内的其他可写通用寄存器是没有意义的。也就是说,我们甚至没有函数栈。因此,在执行到内核的第一条指令时,我们无法使用任何常规的高级语言,必须使用机器码或者汇编。并利用这些代码设置函数栈。
此外,由于 qemu 会从 0x80000000 开始执行,所以我们还必须将入口点的代码放到单独的一个段里面,并在 linker script 中保证这个段的地址从 0x80000000 开始。
编写内核入口的代码
我们可以先编写一个简单的内核入口代码,然后再将其放到一个单独的段中。这个代码的功能很简单,就是设置函数栈,然后调用高级语言的函数(我们这里以 rust_main 命名)。
.section .text.entry
.globl _start
_start:
la sp, boot_stack_top
call rust_main
.section .bss.stack
.globl boot_stack_lower_bound
boot_stack_lower_bound:
.space 4096 * 16
.globl boot_stack_top
boot_stack_top:
由于 RISCV 中栈是向下生长的,所以我们将栈的起始地址设置为 boot_stack_top。
嵌入代码到内核
利用 core::arch::global_asm 宏,我们可以将上面的汇编代码嵌入到内核中。具体来说,我们需要在一个 rust 源文件中加入如下代码:(假设上述代码保存在 entry.asm 文件中)
use core::arch::global_asm;
global_asm!(include_str!("entry.asm"));Supervisor Binary Interface (SBI)
SBI 原理及简介
引子
我们都知道如何写一个 hello world 程序。但是,为什么这个程序可以在终端上打印 hello world 呢?
解答这个问题前,我们需要先把问题简化一些。让我们回到上个世纪,那个真的用打印机作为输出的年代。
打印机的具体实现这里我们不关心,我们只需要知道,操作系统往一个特定的地址写一个特定的数据,打印机终端就能执行一个操作,如打印字符 h 或者打印机换到下一行,这叫做 MMIO (Memory mapping I/O)。(如果你实在是特别好奇为什么这样是可以的,下面列举了一种可行的实现。)
点击查看一种可行的 MMIO 实现
当 CPU 执行到读内存地址时,(在 MMU 翻译到物理地址后,)会向主板上的芯片发送写请求,主板上的芯片会区分地址对应的物理设备(这个设备可能是内存,也可能是输入输出设备,如打印机)。当对应的物理设备是打印机时,会采取硬件所要求的方式正确处理请求。所以说,操作输入输出设备,本质上就是读/写 MMIO 地址(这个地址和一般的地址的形式是一样的)。
什么是 SBI?
从字面意思上,SBI 就是 supervisor 的二进制接口。因此,SBI 的任务就是要为 supervisor(也就是内核)提供支持。
上面的打印字符,就是 SBI 需要实现的功能,因为内核本身并没有这个能力,我们需要通过操作外部设备实现。
除此以外,内核还需要进入 machine mode 做一些操作,那么这个也需要 SBI 提供支持。
SBI 的需求
了解了 SBI 的作用,我们现在需要大概分析一下 SBI 需要提供哪些功能。
SBI 作为 supervisor 的接口,其本身主要是在为 supervisor(也就是内核)服务。
内核大致需要这些接口:(具体要实现的内容可以不一样,取决于你的内核需要什么)
- IO(在控制台输出字符、从控制台读取字符);
- 其他硬件操作(如关机);
- 只能在 machine mode 操作的设置(如计时器、修改一些特权寄存器的特定比特)。
SBI 实现细节
UART
不同于 rCore-Tutorial,在 ACore 中,我们要求自己实现 SBI 的功能。第一阶段中,我们需要实现一个十分简易的 SBI 来在命令行中打印字符。在此之前,我们首先需要了解 UART。它是一种串行通信设备,用于在计算机和外部设备之间传输数据。在维基百科中有着更加详细的介绍。在 ACore 中,我们使用的是 QEMU 的 virt 平台,它的串口设备是一个 NS16550A UART。我们需要实现的 SBI 功能是通过 UART 将字符打印到命令行。
我们利用 MMIO 来和串口设备进行通信。引子对于 MMIO 已经有了简单的介绍,我们在这里再补充一些细节。在正式和串口设备通信之前,我们要初始化串口设备,这个过程需要写入一些特定的值到串口设备的寄存器中,而这些寄存器就是通过 MMIO 的方式映射在内存中的。通过这种方式,我们可以与串口设备协定一些最基础的信息,譬如我们是否开启 FIFO 队列(通过 FCR 寄存器),我们是否开启中断(通过 IER 寄存器)等等。
在初始化完成后,我们就可以通过读写串口设备的寄存器来进行输入输出了。我们可以通过读取 RBR 寄存器来获取串口设备接收到的字符,通过写入 THR 寄存器来发送字符,通过读取 LSR 寄存器来获取串口设备的状态。而这些都依赖于 MMIO。
在 QEMU 模拟的 virt 计算机中串口设备寄存器的 MMIO 起始地址为 0x10000000,在下表被称为 base。连续的 8 个 bit 组成一个寄存器。下表给出了 UART 中每个寄存器的地址和基本含义。
| I/O Port | Read (DLAB=0) | Write (DLAB=0) | Read (DLAB=1) | Write (DLAB=1) |
|---|---|---|---|---|
| base | RBR receiver buffer | THR transmitter holding | DLL divisor latch LSB | DLL divisor latch LSB |
| base+1 | IER interrupt enable | IER interrupt enable | DLM divisor latch MSB | DLM divisor latch MSB |
| base+2 | IIR interrupt identification | FCR FIFO control | IIR interrupt identification | FCR FIFO control |
| base+3 | LCR line control | LCR line control | LCR line control | LCR line control |
| base+4 | MCR modem control | MCR modem control | MCR modem control | MCR modem control |
| base+5 | LSR line status | factory test | LSR line status | factory test |
| base+6 | MSR modem status | not used | MSR modem status | not used |
| base+7 | SCR scratch | SCR scratch | SCR scratch | SCR scratch |
介于篇幅有限,寄存器的详细含义以及如何设置请参考这篇博客。
UART 初始化
UART 的初始化可以参考 xv6,recore 和 uart_16550。
使用 UART 进行输入输出
使用 UART 输入输出主要和 RBR,THR 和 LSR 寄存器进行交互,具体依旧可以参考这篇博客。
在与 RBR 等寄存器的交互过程中,需要使用 volatile 修饰符,以防止编译器对这些操作进行优化。具体请参考 volatile crate。
之后建议参照 rCore-Tutorial 中的介绍,创建 print! 宏与 println! 宏,以方便后续的调试。
使用 QEMU 进行调试
因为我们不使用 rCore-Tutorial 中的 SBI,linker script 需要作出调整。在 rCore tutorial 给出的 linker script 中,其 BASE_ADDRESS 设置为:
BASE_ADDRESS = 0x80200000;
这是因为 rCore 将 SBI 的二进制文件放在了 0x80000000 的位置,所以相应的内核二进制文件被放在了 0x80200000 的位置。而在 ACore 中,我们需要自己实现 SBI,所以我们直接将内核二进制文件放在 0x80000000 的位置即可。所以 linker script 应该被更改为:
BASE_ADDRESS = 0x80000000;
同时, QEMU 的启动参数需要做一些调整:
qemu-system-riscv64 \
-machine virt \
-nographic \
-bios none \
-device loader,file=$KERNEL_BIN,addr=$KERNEL_ENTRY_PA \
-s -S
KERNEL_BIN 表示编译生成的内核二进制文件,KERNEL_ENTRY_PA表示将内核二进制文件载入到的 QEMU 物理内存上的物理地址。由于 QEMU 会固定跳转到 0x80000000,所以这里的 KERNEL_ENTRY_PA 应该是 0x80000000。
-s -S 参数表示启动 QEMU 时暂停 CPU,等待 GDB 连接。默认开启 1234 端口。可以利用 GDB 连接 QEMU,进行调试:
riscv64-unknown-elf-gdb \
-ex "file $KERNEL_ELF" \
-ex "set arch riscv:rv64" \
-ex "target remote localhost:1234"
KERNEL_ELF 表示编译生成的内核 ELF 文件。
当使用 GDB 进入 QEMU 后,使用 x /6i 可以发现进入了 0x1000:
=> 0x1000: auipc t0,0x0
0x1004: add a2,t0,40
0x1008: csrr a0,mhartid
0x100c: ld a1,32(t0)
0x1010: ld t0,24(t0)
0x1014: jr t0
jr t0 之后会跳到 0x80000000,理论上会进入我们的内核,可以继续使用 GDB 进行调试。
TEST
在 QEMU 模拟的 virt 计算机中串口设备寄存器的 MMIO 起始地址为
0x10000000。
这些信息都可以在 QEMU 的源码中找到,譬如 virt_uart0。找到的方法参考自这篇文章。
Shutdown 对应的是 virt_test,其 MMIO 起始地址为 0x100000。与寄存器应如何交互需参考其他 SBI 的实现。
特权级机制
我们这里只会介绍原理和从 M mode 转到 S mode 的方法。
我们已经在操作系统简介中介绍了特权级及其作用。我们知道,特权级机制可以保证应用的运行不会影响到内核或者其他的应用。
整个特权级机制是通过硬件加上指令集支持实现的。CPU 有一些特殊的寄存器,叫做 CSR (Control and Status Register),用于控制和记录特权相关的状态。
我们将从高特权态到低特权态的操作称为 eret (environment return),将低特权态到高特权态的操作成为 ecall。
特权指令
RISCV 大致提供这些特权指令:
| 指令 | 描述 |
|---|---|
ecall | 从低特权态进入高特权态 |
ebreak | 用于调试 |
mret | 从机器态到低特权态,在特权态不正确的情况下执行会产生非法指令异常 |
sret | 从监管态到低特权态,在特权态不正确的情况下执行会产生非法指令异常 |
wfi | 等待中断,在 U mode 下执行会产生非法指令异常 |
sfence.vma | 刷新 TLB,在 U mode 下执行会产生非法指令异常 |
csrr | 读取 CSR(到通用寄存器) |
csrw | 写入 CSR(从通用寄存器) |
csrrw | 读取 CSR 并写入 CSR,这个过程是原子的 |
一些特权寄存器或寄存器位的命名
我们会在 RISCV 的手册中看到一些特权寄存器或寄存器位的命名,但是由于体系结构喜欢用简称来称呼,而简称对于不熟悉的人来说不是很友好,这里我们介绍一些比较常见的命名。
mstatus/sstatus(Machine/Supervisor Status):记录特权级的状态。mpp/spp(Machine/Supervisor Previous Privilege):记录上一次的特权级。mpie/spie(Machine/Supervisor Previous Interrupt Enable):记录上一次的中断使能状态,这是由于当发生中断时,中断会被禁用,以免在处理中断时又发生中断。mepc/sepc(Machine/Supervisor Exception Program Counter):记录上次异常的地址。mcause/scause(Machine/Supervisor Cause):记录异常的原因。mtval/stval(Machine/Supervisor Trap Value):记录异常的附加信息。medeleg/mideleg(Machine Exception/Interrupt Delegation):处理异常/中断的特权态。mie/sie(Machine/Supervisor Interrupt Enable):中断启用。mip/sip(Machine/Supervisor Interrupt Pending):有中断等待。mscratch/sscratch(Machine/Supervisor Scratch):用于保存临时数据,可以利用如csrrw a0, mscratch, a0来交换 mscratch 和通用寄存器的值。satp(Supervisor Address Translation and Protection Register):用于设置虚拟内存映射规则。mtvec/stvec(Machine/Supervisor Trap Handler Vector):用于设置 trap 的处理起始点(发生 trap 之后会跳转到这个地址)。
RISCV 切换特权级原理
我们首先介绍一下 RISCV 中切换特权级的原理。关于具体细节,我们会在后面的内容中介绍。你不需要对整个过程中所有的寄存器都有深入的了解。
典型的特权级切换过程
最通常的同步特权级切换就是系统调用。在一次系统调用中,用户态程序会使用 ecall 指令进入内核为其设置好的处理代码段。这段代码通常会先保存所有的上下文(这阶段不需要保存用户态的 pc,因为已经有寄存器保存了,这个寄存器叫 sepc),然后根据内核的设计,可能会切换页表,然后跳转到内核的 trap 处理代码。完成后,如果内核要返回该应用的用户态,那么会通过 CSR 寄存器设置好应用的环境(包括 ecall 的处理代码),并恢复上下文,然后执行 sret 指令返回用户态。
最通常的异步特权级切换是时间片的中断。时间片中断会进入 M mode,所以为了进入到 S mode,我们需要再进行一次特权级的切换。这个切换可以通过同步或异步的方式完成。
注意在 ecall 和 eret 的过程中,除 pc 以外的通用寄存器都不会被修改。
高特权级到低特权级的同步方式
前面已经举了一个例子,在高特权级到低特权级的过程中,我们通常会设置好应用的环境,然后保存所有的通用寄存器,切换页表(如果需要),最后执行 *ret 指令回到用户态。
低特权级到高特权级的同步方式
低特权级到高特权级是通过 ecall 来实现的,此时 CPU 会跳转到内核设置的处理代码。
异步方式
异步方式是通过中断来实现的。中断会进入到特定状态(取决于是何种特权级的中断)的特定处理代码。
从 M mode 到 S mode
注:从 M mode 到 S mode 的几乎所有操作都是与硬件直接相关的操作,抽象等级很低,不值得深究。
我们现在的内核还没有切换过特权级,也就是说我们现在正在 M mode 下运行。我们需要切换到 S mode 下运行我们的内核。
为了能让我们的内核正确地切换内核,我们大致需要做以下几件事情:
- 设置
mstatus寄存器及mepc寄存器; - 暂时禁用页表;
- 启用中断(为后面时间片调度做准备);
- 配置 Physical Memory Protection,让内核能在 S mode 下访问所有物理内存;
- 启用时钟中断;
- 调用 mret 指令,切换到 S mode。
提示:关于如何设置特权寄存器及其特定字段,请参阅特权寄存器指南。
设置 mstatus 寄存器及 mepc 寄存器
我们需要将 mstatus 寄存器的 MPP 字段设置为 1,这样当我们执行 mret 指令时,我们就会切换到 S mode。然后我们需要将 mepc 寄存器设置为内核 S mode 的入口地址。
暂时禁用页表
将 satp 寄存器设置为 0 即可。
启用中断
首先,将 medeleg 和 mideleg 寄存器设置为 0xffff。
将 sie 寄存器的 SEIE、STIE 和 SSIE 位设置为 1,这样当我们切换到 S mode 时,中断会被启用。
配置 Physical Memory Protection
我们需要将 pmpaddr0 寄存器设置为 0x3fffffffffffff,并将 pmpcfg0 寄存器设置为 0xf。
启用时钟中断
我们需要将 mtimecmp 寄存器设置为一个合适的值,这样当时钟中断到来时,CPU 会跳转到内核的时钟中断处理函数。
间隔的时间一般是 1000000,这样大概 0.1 秒会产生一次时钟中断。
由于 RISCV 中 mtime 和 mtimecmp 寄存器都是 Memory-Mapped 地址的,所以我们只需要操作内存地址即可。
根据 qemu 的 hw/riscv/virt.c 文件,mtime 和 mtimecmp 寄存器的地址分别是 0x0200bff8 和 0x02004000 + 8 * hartid。
在初始化时,我们需要先设置何时的 mtimecmp 寄存器(用 mtime 加上时间间隔)。里面的一些参数可以通过 mscratch 寄存器来传递。
接着,将 mtvec 寄存器设置为时钟中断处理函数的地址(可以暂时找一个空函数占位,也可以暂时不设置后面的 MIE 位,但是记得在后面修改回来)。注意,为了放置上下文被破坏,时钟中断处理函数入口一定是汇编。
然后,通过设置 mstatus 寄存器的 MIE 位来启用 M mode 中断。
最后,通过设置 mie 寄存器的 MTIP 位来使时钟中断生效。
注意:当 mtvec 指向一个空函数时,时钟中断会触发,但是不会有任何效果,而且会导致 CPU 一直处于中断状态(因为 mtimecmp 并没有被重置)。
调用 mret 指令
最后,我们需要调用 mret 指令,切换到 S mode。
内存分配器
静态分配和动态分配
我们先考虑用户态程序的内存分配问题。内存分配的方式可以分为静态内存分配和动态内存分配
静态内存分配是程序运行前在编译阶段由编译器确定的,不能在运行时进行改变。其通常在堆栈(stack)中分配。
静态内存分配显而易见的问题是不够灵活,无法适应一些需要动态分配内存的情况。一个经典的例子是变长数组,在 Rust 中则是 std::vec::Vec。
与静态内存分配不同,动态内存分配的大小和生命周期在编译时并不确定,而是在运行时进行决定和分配。例如 C 中的 malloc 和 free:
void* malloc (size_t size);
void free (void* ptr);
malloc 用于分配一块指定大小的内存,free 用于释放之前分配的内存。这种动态内存分配的方式更加灵活,但也更加复杂,需要程序员自己管理内存的生命周期。
在 malloc 和 free 的背后,是用户态的内存分配器,它负责管理内存的分配和释放,当内存不够时使用 sbrk 或 mmap 向操作系统申请更多的内存。其如何实现可以参考 Malloc Lab。
让我们回到 kernel。我们在 kernel 中也有使用 Vec、Box 和 Map 的需要。但在我们的 kernel 中,由于 #![no_std] 的存在,我们无法使用 std::alloc 中的内存分配器,自然也就无法使用以上的数据结构。但 Rust 在 std 之外提供了 alloc crate,我们可以使用这个 crate 来使用其中提供的 alloc::vec::Vec,但前提是我们需要自己实现一个内存分配器。
Rust 中的 GlobalAlloc
Trait GlobalAlloc 的定义可以在这里找到,其接口如下:
pub unsafe trait GlobalAlloc {
// Required methods
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
// Provided methods
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
unsafe fn realloc(
&self,
ptr: *mut u8,
layout: Layout,
new_size: usize
) -> *mut u8 { ... }
}GlobalAlloc 定义了 alloc 和 dealloc 两个方法,分别用于分配和释放内存。你写的 heap allocator 需要实现 GlobalAlloc 这个 trait,且具体有以下要求:
alloc:返回一个指向分配的内存的一个字节的指针,如果分配失败则返回null。dealloc:释放之前分配的内存。要求这块内存之前是通过alloc分配的。
一个不能用的示例如下:
pub struct Dummy;
unsafe impl GlobalAlloc for Dummy {
unsafe fn alloc(&self, _layout: Layout) -> *mut u8 {
null_mut()
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
panic!("dealloc should be never called")
}
}以上代码参考自这篇文章,更多的信息也可参考之。
Rust 中的堆数据结构
在 kernel 中能使用的数据结构来自于 alloc 这个 crate,其提供的数据结构与 std 中的数据结构类似但并不完全相同,且实现方式也可能不一致。里面可能有用的 modules 列举如下:
- box:提供了
Box这个数据结构,用于分配在堆上的数据。 - collections:提供了
BinaryHeap、BTreeMap、BTreeSet、LinkedList、VecDeque。 - rc:提供了
Rc和Weak。 - str:提供了
str。 - string:提供了
String。 - vec:提供了
Vec。
Buddy Allocator
算法介绍
The buddy system assumes that memory is of size 2N for some integer N . Both free and reserved blocks will always be of size 2k for k <= N . At any given time, there might be both free and reserved blocks of various sizes. The buddy system keeps a separate list for free blocks of each size. There can be at most 2k such lists, because there can only be 2k distinct block sizes.
When a request comes in for m words, we first determine the smallest value of k such that 2k >= m . A block of size 2k is selected from the free list for that block size if one exists. The buddy system does not worry about internal fragmentation: The entire block of size 2k is allocated.
If no block of size 2k exists, the next larger block is located. This block is split in half (repeatedly if necessary) until the desired block of size 2k is created. Any other blocks generated as a by-product of this splitting process are placed on the appropriate freelists.
The disadvantage of the buddy system is that it allows internal fragmentation. For example, a request for 257 words will require a block of size 512. The primary advantages of the buddy system are:
- there is less external fragmentation;
- search for a block of the right size is cheaper than, say, best fit because we need only find the first available block on the block list for blocks of size 2k ; and
- merging adjacent free blocks is easy.
The reason why this method is called the buddy system is because of the way that merging takes place. The buddy for any block of size 2k is another block of the same size, and with the same address (i.e., the byte position in memory, read as a binary value) except that the kth bit is reversed. For example, the block of size 8 with beginning address 0000 in the figure below, has buddy with address 1000. Likewise the block of size 4 with address 0000 has buddy 0100. If free blocks are sorted by address value, the buddy can be found by searching the correct block size list. Merging simply requires that the address for the combined buddies be moved to the freelist for the next larger block size.
以上片段参考自 Memory Management Tutorial Section 2.3 - Buddy Methods。
还有一些别的参考材料:wikipedia,recore wiki。
如何开始
首先,我们需要划分一块区域作为内存池。一种简单的方式就是直接使用 static 变量,即全局变量:
static mut KERNEL_HEAP_SPACE: [u8; KERNEL_HEAP_SIZE] = [0; KERNEL_HEAP_SIZE];然后在这段空间上实现 buddy allocator。
页表
页表的目的,在于将不连续的内存变成连续的内存地址空间。页表提供了一个内存地址的抽象,让原本可能并不连续的内存在页表的映射下变成了连续的内存。此外,页表还能够为一个页设置访问权限,并记录页面的访问读写情况。
总结来说,页表有着以下好处:
- 重新映射地址与内存页,提供内存地址抽象;
- 设置访问权限(包括读/写/执行/用户态可用/全局可用等);
- 记录页面访问/读写情况。
不过,我们注意到,如果我们要为每一个虚拟页建立映射,那么我们需要建立 \(2^{64-12}\) 个映射,这会耗费大量的内存,而且一个程序只会使用很少的一部分虚拟地址空间。多级页表就是用来解决这个问题的。多级页表会从先按照虚拟地址的高位,映射到下一级页表中,如果这个虚拟地址没有被使用,那么下一级页表就无需存在。这样,很多个映射被合并到一个更高层次的映射,内存被大大节约了。而且,由于使用了多级页表,每一张页表占用的空间也比原来少了很多(在后面的 SV39 下一张页表是一个页的大小),因此避免了需要找到连续大内存的问题。
硬件会将最高级的页表地址记录在一个特权寄存器上(在 RISCV 上是 satp 寄存器,全称是 supervisor address translation and protection register)。当硬件想要知道一个虚拟地址在何处时(不考虑 TLB),会依次读取各级页表,翻译出物理内存的位置。
SV39 多级页表机制
我们的内核使用的是 SV39 多级虚拟内存机制。SV39 采用三级页表映射,每一级控制 \(2^{9}\) 个表项,每个表项占用 8 bytes,所以一张页表(无论哪一级)占用了 4 KiB,也就是一个页的大小。下面是虚拟地址和物理地址的映射示意图:(其中 VPN 表示 virtual page number,PPN 表示 physical page number)
38 30 29 21 20 12 11 0
+-----------+-----------+------------+---------------+
| VPN[2] | VPN[1] | VPN[0] | page offset |
+-----------+-----------+------------+---------------+
55 30 29 21 20 12 11 0
+-----------------+-----------+------------+---------------+
| PPN[2] | PPN[1] | PPN[0] | page offset |
+-----------------+-----------+------------+---------------+
每一级页表控制 \(2^{9}\) 个表项,所以可以控制 9 bits 的地址空间。最后一级控制的是 4 KiB 的页面,所以我们一共可以控制 \(12 + 9 \times 3 = 39\) bits 的虚拟地址空间,SV39 的 39 就是这样来的。
关于页表项,请参见SV39 的页表项。
SV39 映射举例
假设我们现在有一个地址 0x7FFFFFFFFF(也就是低 39 bits 都是 1,其他高位都是 0),我们来看看虚拟地址是如何映射的。
- 通过
satp寄存器找到第一级页表; - 翻译 30-38 这几位,找到第二级页表,如果发现这个地址非法,那么停止翻译,进入异常处理流程;
- 翻译 21-29 这几位,找到第三级页表,如果发现地址非法,处理同上;
- 翻译 12-20 这几位,找到对应的物理的 12-55 位。
翻译完成的物理内存有两部分,一部分是刚刚翻译的 12-55 位,另一部分是页面上的偏移,即虚拟地址的 0-11 位。
SV39 页表项
页表项,用于表示映射信息,其英文为 page table entry(简称为 PTE)。
页表项如下所示:
63 54 53 28 27 19 18 10 9 8 7 6 5 4 3 2 1 0
+----------+----------+----------+----------+-----+-+-+-+-+-+-+-+-+
| reserved | PPN[2] | PPN[1] | PPN[0] | RSW |D|A|G|U|X|W|R|V|
+----------+----------+----------+----------+-----+-+-+-+-+-+-+-+-+
10 26 9 9 2 1 1 1 1 1 1 1 1
其中:
V:有效位,表示页表项是否 valid。R, W, X:这些位分别表示页面是否可读、可写和可执行。当所有三个都为零时,PTE 指向页面表的下一级;否则,它是一个 leaf PTE。U:用户位,表示对应虚拟页面是否可在用户态下访问。G:全局位,表示对应的页面是否是全局的。对于 non-leaf PTE,全局设置意味着页表后续级别中的所有映射都是全局的。请注意,未能将全局映射标记为全局只会降低性能,而将非全局映射标记为全局则是一个致命错误。A:访问位,表示对应的页面是否被访问过。D:脏位,表示对应的页面是否被写过。RSW:为内核程序预留,硬件不会对此做任何其他操作。
下表列出了所有可能的 R, W, X 组合:
| X | W | R | Meaning |
|---|---|---|---|
| 0 | 0 | 0 | Pointer to next level of page table. |
| 0 | 0 | 1 | Read-only page. |
| 0 | 1 | 0 | Reserved for future use. |
| 0 | 1 | 1 | Read-write page. |
| 1 | 0 | 0 | Execute-only page. |
| 1 | 0 | 1 | Read-execute page. |
| 1 | 1 | 0 | Reserved for future use. |
| 1 | 1 | 1 | Read-write-execute page. |
SV39 的具体翻译过程
在页表文档中,我们大致介绍了翻译的流程,所以这里我们只举例中间的某一层页表翻译过程。
由于页表是按照页大小对齐的,所以页表的地址后 12 位全零,因此很多时候不用特别指定。
假设我们要翻译某一层的虚拟地址 (VPN),记为 \(v\),页表起始位置位于 \(pt\)(后 12 位全零)。
由于每一层都是 9 位,而页表项都是 8 bytes,因此对应的页表项起始位置位于 \(pt+v \times 8\),这样我们就拿到了页表项。页表项将会指向一个地址 \(p\)(只知道 12-55 位,其他为可以认为全零),12-55 位可以通过三个 PPN 相拼得到。
接着,我们进行一些访问合法性的验证(如验证有效位,用户态下验证是否用户是否可访问等),如果没有通过验证,就会产生异常。
最后,检查页表是否为叶子节点。如果 RWX 都是零,则不是叶子节点,其指向的地址 \(p\)(前面已经给出的计算方法)为下一级页表的起始位置;否则,页表项位叶子节点,其指向的地址加上剩下未映射的部分即为映射到的物理地址。
延伸内容:大页
我们注意到映射很多个页面时,会占用很多个页表项。如果有很多个页面是连续的(如 \(2^9\) 个对齐且连续的页面,这在 buddy allocation 中很常见),那么其实不需要这么多页表项。
RISCV 提供了大页映射的方案,可以映射 2 MiB 以及 1 GiB 的页面。对于 1 GiB 的大页,只需要在第一级页表上设置大页的 RWX 权限即可,不需要为下面的所有页面设置单独的页表项。同理,对于 2 MiB 的大页,只需要在第二级页面设置权限即可。
应用程序执行环境
前面我们已经建立了一个较为完整的内核基础环境。现在,我们要为应用程序提供执行环境,让应用程序可以正常地执行。
应用程序需要运行在用户态,因此我们需要进行内核态到用户态的特权态转换。不过,光从内核态转到用户态是不够的,在一些特定情况下,应用需要内核的服务,如系统调用。比如应用如果想要操作一个文件,其自身是无法完成的,必须由内核完成。关于具体的操作,请参见用户态与内核态切换页面。
在内核态到用户态切换前,我们还需要为用户态建立自身的地址空间,并在内核中记录一些应用的信息。
由于应用程序执行环境相关的内容之间关联性比较高,本章节内容的顺序按照逻辑顺序编排,与写代码的顺序不完全一致,因此建议完整阅读完之后再进行实现,或者在实现功能时预留相关代码的位置。
在我们作业的早期阶段,我们暂时只需要创建单个用户进程。不过,对于一个内核来说,仅仅有一个进程是远远不够的,因此在完成单进程后,我们需要支持多用户进程。我们要求多用户进程必须通过时间片共享 CPU 资源,而不是按照顺序逐个执行任务。
在多用户进程的内核上,除了前面所说的应用地址空间、记录应用信息、用户态与内核态切换以外,我们还需要加入一些管理模块。管理模块包括进程管理(管理应用地址空间及应用信息)、调度模块、驱动模块。
记录应用信息
每个应用有很多信息需要记录,如使用的内存、页表、打开的文件等等。通常我们会将这些信息放在一起。在 linux 中,有一个叫 task_struct 的 struct 来储存这些信息。
我们现在不需要包含所有的信息,推荐在后面根据需求逐步添加。后面的文档中,我们会用 task_struct 来指代这个储存信息的结构。我们不要求作业中一定要使用与之一样的名称。
用户态与内核态切换
用户态与内核态切换分为两个操作,一个是从内核态到用户态,另一个是从用户态到内核态。由于用户态不能任意跳转到内核态的内存(不然基于特权级权限保护就没用了),我们必须在切换到用户态前设置好回到内核态的地址。
另外,在用户态与内核态切换时,通常我们需要切换页表(也有一些实现是不需要的)。在切换页表的时候,我们必须保证切换前后 pc 所在的内存是合法的。通常我们会使用 trampoline(蹦床)机制来完成从内核态与用户态的切换。以内核态切换到用户态为例,我们会先从内核地址跳到 trampoline,然后再从 trampoline 跳到用户态。请注意,如果内核所在的地址可能会与应用的地址空间冲突,那么必须使用 trampoline 机制。
因此,内核态进入用户态前,我们需要设置好用户态的环境(如 spp 设置为用户态),在内核地址空间储存必要的信息,在用户内存空间 (trap context) 储存恢复到内核态的信息(如内核的页表地址、内核栈地址等)。完成这些操作后,我们需要跳转到 trampoline,通过 trampoline 设置好用户的页表,并通过 sret 返回用户态。
第一次从内核态进入用户态的过程和之后从内核态进入用户态的过程实际上是一样的,所以我们一般会将两者合到一起。
在进行一些核心操作时,你需要先暂时禁用 S mode 的中断,以免在切换过程中发生中断,导致内核的不一致。在发生中断时,你无需手动禁用中断,因为 RISCV 特权指令集规定了在发生中断时,中断会自动被禁用,知道手动设置了允许中断。
Trampoline
关于 trampoline,我们需要写的内容包括:编写 trampoline 的代码、在内核和用户态的地址空间中设置 trampoline。
编写 Trampoline 的代码
在进入 trampoline 时,我们不能破坏除了 pc 以外的所有寄存器,因此代码必须是由汇编编写(而且不能内联汇编)。而且,由于 trampoline 是以页面为单位的,所以 trampoline 的起始位置必须按照页面对齐。
设置起始位置对齐
我们需要为 trampoline 单独设置一个段,并在 linker script 中设置按页对齐。比如 trampoline 在 .trampoline 段,那么我们需要在 linker script 中修改为:(注意:如果你的段名称是 .text. 开头的,请把 trampoline 段放到 *(.text .text.*) 前面,并把进入内核的第一行代码放到 trampoline 前面,以免进入错误的内核起始点。
...
.text : {
*(.text .text.*)
. = ALIGN(0x1000);
_trampoline = .;
*(.trampoline)
. = ALIGN(0x1000);
ASSERT(. - _trampoline == 0x1000, "error: trampoline size is not a page size");
}
...
_trampoline 和 ASSERT 是保证了 trampoline 会正好占用一个页,以免在内核设置地址时发生错误。
在 trampoline 的汇编中,我们需要将 trampoline 设置为之前指定的段:
.section .trampoline
... # Your code here
编写 Trampoline
Trampoline 中一般有两个函数,一个是从用户态进入到内核态的 trap vector,另一个是从内核态进入到用户态的 trap return 函数。这两个函数虽然在用户态和内核态都可见,但是实际使用时,CPU 都已经处于 S mode。
此外,为了方便计算函数偏移量(因为 trampoline 不在内核 linker script 指定的地址,而是在一个用户态和内核态都不会用到的地址),我们还可以加一个 trampoline 起始地址。当然,我们也可以使用 trampoline 中的第一个函数,不过这看起来不太优雅。
从用户态到内核态的函数(这里我们将这个函数成为 user_trap)需要做这几件事情:
- 将寄存器 x1-x31 记录到 trap context 中(提示:你可以利用 scratch 储存临时变量);
- 将内核的 sp 寄存器设置为 trap context 中储存的内核 sp 地址;
- 将内核处理 trap 的函数地址暂存到某个寄存器中;
- 切换到内核页表(提示:请这样切换页表);
- 跳转到内核处理 trap 的函数(注意:为了避免出现相对地址的情况,建议将返回地址存在 trap context 中)。
从内核态到用户态的函数(这里我们将这个函数称为 user_return)需要做这几件事情(假设 stvec、sstatus、sepc 已经设置妥当,用户页表可以作为入参传入此函数,亦可储存于 trap context 中):
- 切换到用户页表(提示:请这样切换页表);
- 将 trap context 中储存的用户寄存器 x1-x31 恢复;
sret返回用户态。
在内核和用户态的地址空间设置 Trampoline
通常情况下,我们会将 trampoline 放在内核地址空间的最高位置,也就是 \(2^{39}-4096\) 处。我们需要在内核页表和所有的用户页表中将这个地址映射到 trampoline 实际的地址。
处理用户态的 Trap
用户态时如果发生中断或异常,都会进入 stvec 所指定的地址。这个地址就是我们前面所说的 trampoline。不过 trampoline 只会完成最基础的工作如保存上下文,切换页表等。完成这些之后,我们可以进入到内核中,使用高级语言完成更多的工作。
Trampoline 的 user_trap 最后会跳转到一个内核中的函数,这个函数需要进一步记录一些信息(如 sepc,这些信息可以储存在函数栈中),识别中断或异常的原因,并调用相应的处理函数。
识别中断或异常的原因
在 S mode 的 trap 中,储存 trap 原因的寄存器为 scause。scause 的低 63 位是 trap 的原因,最高位为 0 表示异常,为 1 表示中断。其余位表示异常或中断的原因。下表是 RISCV 的手册中所写的 scause 在不同情况下的含义。
| Interrupt | Exception | Description |
|---|---|---|
| 1 | 0 | Reserved |
| 1 | 1 | Supervisor software interrupt |
| 1 | 2-4 | Reserved |
| 1 | 5 | Supervisor timer interrupt |
| 1 | 6-8 | Reserved |
| 1 | 9 | Supervisor external interrupt |
| 1 | 10-15 | Reserved |
| 1 | \(\ge\)16 | Designated for platform use |
| 0 | 0 | Instruction address misaligned |
| 0 | 1 | Instruction access fault |
| 0 | 2 | Illegal instruction |
| 0 | 3 | Breakpoint |
| 0 | 4 | Load address misaligned |
| 0 | 5 | Load access fault |
| 0 | 6 | Store/AMO address misaligned |
| 0 | 7 | Store/AMO acess fault |
| 0 | 8 | Environment call from U-mode |
| 0 | 9 | Environment call from S-mode |
| 0 | 10-11 | Reserved |
| 0 | 12 | Instruction page fault |
| 0 | 13 | Load page fault |
| 0 | 14 | Reserved |
| 0 | 15 | Store/AMO page fault |
| 0 | 16-23 | Reserved |
| 0 | 24-31 | Designated for custom use |
| 0 | 32-47 | Reserved |
| 0 | 48-63 | Designated for custom use |
| 1 | \(\ge\)64 | Reserved |
我们不一定要完全将这所有的错误原因都处理。如 breakpoint 问题,正常情况下是不会遇到的。
在中断的所有 scause 中,我们只会遇到 supervisor software interrupt(软中断)和 supervisor external interrupt(外部中断)。软中断通常被用来在时钟中断时发起。外部中断意味着有硬件触发了中断。这个设备可以是 UART,也可以是 VIRTIO 的 IRQ(后面会在 FS 中介绍)。
在异常的所有 scause 中,较为常见的是 environment call from U-mode,也就是用户态发起的系统调用。此外,你还可以按需处理各种 page fault,以及其他的错误。
Debug
scause 寄存器是一个很好的调试信息。你可以在 trap 处理函数中打印这个值,以便更好地了解发生了什么。
当你的程序出现了异常,你可以通过这个值来判断异常的原因。比如,如果你的程序出现了 page fault,你可以通过 scause 的值来判断是哪种 page fault,然后进一步调试。
系统调用 (System Call)
应用程序很多时候需要内核提供一些服务,而这些服务的管理必须通过内核完成,比如读取、写入一个文件,因此,应用程序需要主动地通过同步的方式进入内核,这个方式称为系统调用。
RISCV 中系统调用的实现
在 RISCV 中,系统调用是通过 ecall 指令来实现的。ecall 会产生一个异常,scause 中体现为 Environment call from U-mode。当我们在 trap 时识别到了这个异常,我们就知道这是应用发起了一个系统调用。
不过,仅仅通过 scause,我们只能知道发生了一个系统调用,却无法知道系统调用具体要做什么。通常情况下,我们会利用通用寄存器来传递参数。系统调用的形式和普通的函数调用类似,因此我们一般也会遵守 calling convention 来传递参数。
我们知道 RISCV calling convention 规定了传递参数是通过 a0-7 实现的。此外,我们注意到不同的需求会产生不同的系统调用,比如将一些数据写入文件需要提供足以确定文件的信息以及数据,而建立目录则只需要目录名即可(可能还要加上权限)。因此,我们需要一个系统调用编号来区分不同的系统调用。
我们不妨将系统调用号放在 a0 寄存器中,将其他参数放在 a1-7 中。这样,我们就可以通过 a7 来识别系统调用的类型,通过 a0-6 来传递参数。(当然,我们也可以将系统调用号放在 a1 中,这样就可以使用 a1-7 来传递参数。)
因此,在用户态发起系统调用时,我们需要将系统调用号放在 a7 中,将参数放在 a0-6 中,然后执行 ecall 指令。
ecall 会触发异常,进入到 trampoline 中的 user_trap 函数,user_trap 函数会将通用寄存器保存在 trap context 中,因此 a0-7 的值也会被保存在此处。
user_trap 最后会调用内核中的函数(通常这个函数是由高级语言编写的),来进一步处理函数。这个函数在上一节已经讨论过了。这个函数会识别到这是一个系统调用,然后通过系统调用编号找到合适的处理函数。
系统调用的返回值通常是通过 a0 传递的。因此,我们在处理完系统调用后,将返回值放在 a0 中(其实是 trap context 中),然后返回到用户态。
大数据传递
我们注意到系统调用的参数主要是通过寄存器传递的。不过,有时候,我们需要传输很多数据,比如写入文件。这时候,我们可以通过内存来传递数据。
注意到按照我们的实现,内核和用户的页表是不同的,而且用户的数据可能是跨页的,这时我们就无法很方便地读取数据。一个常规的实现是内核切换到一个临时的页表,然后将用户的数据拷贝到内核的内存中,或者将内核的数据拷贝到用户的内存中,然后再进行处理。通常实现这两个过程的函数叫做 copy_from_user 和 copy_to_user。
除了上面所说的实现,其实还有很多种实现方式,比如在用户地址空间中加若干个用于传递数据的页(其实一个页基本就够了,如果不止一个页,则需要保证在内核中这些页的地址是连续的)。对于从用户地址传输到内核地址空间的情况,我们需要在系统调用前将数据拷贝到这个页中;对于从内核地址空间传输到用户地址空间时,我们需要在系统调用返回前将数据拷贝到用户的内存中。
系统调用库
为了方便编写用户程序,通常我们需要提供一个系统调用的库,这个库会封装系统调用的细节,提供更加友好的接口。比如,我们可以提供一个 write 函数,这个函数会将数据写入到文件中,而不需要用户关心系统调用的细节。
用户态程序
我们前面已经准备好了应用程序的执行环境,接下来,我们就可以编写用户态程序了。
为了方便编写用户态程序,我们一般会提供一个用户库,其中包含了系统调用的接口,以及一些容易使用的接口。
另外,应用通常是一个可链接的执行文件 (ELF, Executable and Linkable Format),我们需要了解如何将应用编译成 ELF 文件。在制作 ELF 时,我们还需要指定应用的地址空间。
测试用户态程序
我们提供了一些简单的测试方法,包括:
仅测试用户态程序能否运行(无 ELF、无系统调用)
利用下面的程序,我们可以在没有实现 ELF 和系统调用的情况下,测试用户态程序是否能够运行。运行前,请确保这个程序的地址空间中 0x10000000 地址(UART 的物理基地址)已经被映射到了 0x10000000 地址。和一般程序不同,这个程序是从 pc 为 0 开始执行的。
let program: [u32; 4] = [
0x10000537, // lui a0,0x10000
0x0310059b, // addiw a1,zero,0x31
0x00b50023, // sb a1,0(a0)
0xbfd5 // j 0
];如果程序能够正常运行,那么其将会不断打印字符 1。
测试调度是否正确(无 ELF、无系统调用)
利用下面的程序,我们可以在没有实现 ELF 和系统调用的情况下,测试调度是否正确。运行前,请确保两个程序的地址空间中 0x10000000 地址(UART 的物理基地址)已经被映射到了 0x10000000 地址。和一般程序不同,这个程序是从 pc 为 0 开始执行的。
let program1: [u32; 4] = [
0x10000537, // lui a0,0x10000
0x0310059b, // addiw a1,zero,0x31
0x00b50023, // sb a1,0(a0)
0xbfd5 // j 0
];
let program2: [u32; 4] = [
0x10000537, // lui a0,0x10000
0x0320059b, // addiw a1,zero,0x32
0x00b50023, // sb a1,0(a0)
0xbfd5 // j 0
];如果程序能够正常运行,那么控制台将会不断交替打印字符 1 和 2。
系统调用接口
在编写用户程序时,最简单的调试方式就是输出信息。但是,用户程序如何才能输出信息呢?答案是通过系统调用。
系统调用是操作系统内核提供给用户程序的一组标准接口。通过系统调用,用户程序可以请求内核提供各种服务,例如文件读写、进程管理、网络通信等。系统调用是用户程序与内核之间通信的桥梁。
在系统调用这一节中,我们已经讨论了系统调用的实现原理。在这一节中,我们将讨论用户程序如何调用系统调用。
实现接口
以 SYSCALL_WRITE 为例,我们来看看如何在用户态实现系统调用接口。当程序运行在用户态 (U mode) 时,可以通过 ecall 指令触发系统调用。因此,用户态的系统调用接口本质上就是通过 ecall 指令进入内核态,由内核处理系统调用请求。
ecall 指令会触发一个特殊的异常 (exception),称为环境调用 (environment call)。内核的异常处理程序可以识别这种异常,进一步根据 a7 寄存器的值确定具体的系统调用类型,并调用相应的处理函数。而在用户态,我们只需要将系统调用号放在 a7 寄存器,其他参数依次放在 a0~a6 寄存器中,然后执行 ecall 指令即可。下面是一个通用的系统调用接口实现:
fn syscall(id: usize, args: [usize; 7]) -> isize {
let mut ret: isize;
unsafe {
asm!(
"ecall",
inlateout("a0") args[0] => ret,
in("a1") args[1],
in("a2") args[2],
in("a3") args[3],
in("a4") args[4],
in("a5") args[5],
in("a6") args[6],
in("a7") id,
);
}
ret
}其中,id 表示系统调用号,需要与内核定义一致。args 是一个最多包含 7 个参数的数组,传递给内核的系统调用处理函数。
有了这个通用接口,我们可以进一步封装出更易用的系统调用函数。以 SYSCALL_WRITE 为例:
pub fn sys_write(fd: usize, buffer: &[u8]) -> isize {
syscall(
SYSCALL_WRITE,
[fd, buffer.as_ptr() as usize, buffer.len(), 0, 0, 0, 0],
)
}类似的,SYSCALL_READ 系统调用的封装如下:
pub fn sys_read(fd: usize, buffer: &mut [u8]) -> isize {
syscall(
SYSCALL_READ,
[fd, buffer.as_mut_ptr() as usize, buffer.len(), 0, 0, 0, 0],
)
}用户库
基于 sys_write 和 sys_read 等系统调用封装函数,我们可以进一步实现一些常用的用户库函数,使得用户程序更方便地使用系统服务。例如,实现 putchar 和 getchar 函数:
const STDIN: usize = 0;
const STDOUT: usize = 1;
pub extern "C" fn putchar(c: u8) {
sys_write(STDOUT, &[c]);
}
pub extern "C" fn getchar() -> u8 {
let mut buf = [0u8; 1];
sys_read(STDIN, &mut buf);
buf[0]
}这样,用户程序就可以直接调用 putchar 和 getchar 来输出/输入单个字符,而无需关心底层的系统调用细节。
此外,通常用户库也会实现一些更高级的接口,如 println! 宏、read_line 函数等,以提供更方便的功能。
从应用到 ELF
Layout
在 Cargo Package Layout 中,我们介绍了常见的 Rust 项目布局。类似地,为了编写且编译用户程序,我们可以采取以下布局:
.
└── user/
├── lib.rs
├── main.rs
└── bin/
├── hello.rs
├── print.rs
└── ...
执行 cargo build 之后,我们会在 user/target/$(TARGET)/$(MODE) 目录下生成用户程序的 ELF 文件。其中,$(TARGET) 是目标平台(理论上只能是 riscv64gc-unknown-none-elf),$(MODE) 是编译模式(debug 或 release)。
Link
Link 中最重要的是我们需要制定 .text 的位置,这样我们才能在内核中正确加载用户程序。
objcopy
使用 objcopy 可以将 cargo build 生成的 ELF 文件删除所有 ELF header 和符号得到 .bin 后缀的纯二进制镜像文件,例如:
rust-objcopy --binary-architecture=riscv64 --strip-all -O binary target/riscv64gc-unknown-none-elf/debug/user target/riscv64gc-unknown-none-elf/debug/user.bin
之后我们需要把 binary 文件加载进内存,并让内核理解并执行之。关于内核读取 ELF 的部分,将在下一章节中讲解。
应用地址空间
Overview
这里对应用地址空间的布局进行简单介绍:
.text:这个区域包含应用程序的代码。它是只读的,以防止程序意外更改其代码,且它是可执行的。.rodata:即 Read Only Data。顾名思义,这部分包含只读的数据,如代码中使用的常数。这部分显然是不可执行的。.data:这个段通常包含初始化的全局和静态变量。可读且可写,但不可执行。.bss:这个区域包含未初始化的全局和静态变量。这些是程序运行时将被填充的内存区域,但在程序开始时并不需要保存有意义的数据。因此,这个段通常被初始化为零。可读且可写,但不可执行。stack:用来保存局部变量和函数调用信息函数栈。它向更低的内存地址增长。可读且可写,但不可执行。trap context:这部分用于在处理中断或者陷阱(如系统调用)时保存 CPU 的状态。当陷阱发生时,内核保存当前上下文(寄存器,指令指针等),做完其工作后恢复 trap context。trampoline:这是一小段代码,用于在执行系统调用或处理中断时页表的切换以及上下文的切换。guard page:guard page 用于在溢出或越界访问时触发异常。
Layout
以下展示了 rCore 中的应用地址空间布局:
+------------------------+ <- end of address space (2^64 Byte)
| trampoline |
+------------------------+
| trap context |
+------------------------+
| .... | <- empty
+------------------------+
| stack |
+------------------------+
| guard page |
+------------------------+
| .bss |
+------------------------+
| .data |
+------------------------+
| .rodata |
+------------------------+
| .text |
+------------------------+
| unallocated |
+------------------------+ <- start of address space
rCore 中的 user stack 是定长的,并不是很优秀的设计。可以删去 guard page,在进程初始时并不分配栈空间,等到程序有需要,触发 page fault 之后再分配,以节省内存。
Load ELF
我们现在对于应用程序的加载是通过 ELF 文件来进行的。我们需要解析 ELF 文件,将其加载到内存中。我们可以借用 xmas_elf crate 来加载 ELF 文件。利用 xmas_elf 来读取不同的 map areas,并相应的配置 page table,大致如下(节选自 rCore):
let elf = xmas_elf::ElfFile::new(elf_data).unwrap();
let elf_header = elf.header;
let magic = elf_header.pt1.magic;
assert_eq!(magic, [0x7f, 0x45, 0x4c, 0x46], "invalid elf!");
let ph_count = elf_header.pt2.ph_count();
for i in 0..ph_count {
let ph = elf.program_header(i).unwrap();
if ph.get_type().unwrap() == xmas_elf::program::Type::Load {
let start_va: VirtAddr = (ph.virtual_addr() as usize).into();
let end_va: VirtAddr = ((ph.virtual_addr() + ph.mem_size()) as usize).into();
let mut map_perm = MapPermission::U;
let ph_flags = ph.flags();
if ph_flags.is_read() { map_perm |= MapPermission::R; }
if ph_flags.is_write() { map_perm |= MapPermission::W; }
if ph_flags.is_execute() { map_perm |= MapPermission::X; }
todo!("map the segment to memory in page table");
}
}多任务
前面我们已经基本把单任务场景介绍完全了。不过,单任务在现代内核上是远远不够的,因为这意味着我们一次只能执行一个任务。我们需要在一个设备上同时做多件事情,比如同时播放音乐、编译代码、编辑文档等等。
要并行地执行多任务,我们需要使用时间片进行多任务切换。当到时间片末尾时,内核会停止当前任务并切换到下一个任务。这样,我们就可以在一个设备上同时执行多个任务了。决定何时切换任务的服务叫做 scheduler,管理进程信息的服务叫做 process manager。
实现要求
在我们的系统中,为了简单起见,我们一共需要实现以下几个 service:
- Scheduler (S mode)
- Drivers (U mode)
- File system (U mode)
- Process manager (U mode)
Overview
在这一章节中,我们将会实现一个简单的多任务系统。我们将会以 Unix 中的多进程用例作为引入,然后逐步实现我们的多任务系统。
Unix 多进程用例
在这一章节中,我们会介绍 Unix 的多进程使用方法。Unix 的系统调用形式非常精简,因此经常被用于教学。我们会通过一个简单的例子来展示如何使用 Unix 的系统调用来创建进程、等待进程结束、以及进程间通信。以下代码均作示例用,与我们最终的实现无关。
系统调用
Unix 多线程相关的系统调用主要有:
fork:创建一个新的进程。exec:加载一个新的程序。exit:结束当前进程。wait:等待一个子进程结束。
fork
fork 系统调用比较有趣,在内核看来,它表示应用需要创建一个新的子进程,其地址空间与父进程相同,下一个执行的指令也相同,唯一不同的是返回值。父进程中的返回值是子进程的 PID,而子进程中的返回值是 0。这样,父进程和子进程可以通过返回值来区分自己是父进程还是子进程。如果 fork 失败,将会向调用进程返回 -1。
在用户看来,fork 会在原来程序的基础上,复制出一个新的子进程,这个子进程会从 fork 之后的指令开始执行。fork 的返回值用来告诉用户当前是父进程还是子进程。
在程序看来,fork 调用后,会返回一个 int 用于区分当前是父进程还是子进程。而且,从程序的视角看,我们无需太过考虑多进程这件事,因为程序的自己永远都在自己的地址空间上运行。
你可能对上面的表述有一些疑惑,下面我们将用一个例子来展示 fork 的用法。
#include <stdio.h>
int main() {
int pid = fork();
if (pid < 0) {
printf("fork failed\n");
} else if (pid == 0) {
printf("I am child process\n");
} else {
printf("I am parent process\n");
}
return 0;
}
在这个例子中,如果 fork 成功,父进程会输出 I am parent process,而子进程会输出 I am child process。
exec
fork 虽然可以创建出一个新的进程,但是这个进程的地址空间和原来是一样的,因此如果我们要运行一个完全不一样的程序,那么 fork 的功能就不够了。这时候我们就需要 exec 系统调用。
exec 会加载一个新的程序到当前进程的地址空间中,并且开始执行这个程序,也就是「变身」。通常 exec 不会返回,除非出现了错误。
exec 是一类系统调用,包括 execl、execv、execle、execve、execlp、execvp 等(具体请自己查阅 manual page,如执行 man 2 execve)。这些系统调用的区别在于参数的传递方式和搜索路径的不同。
下面是一个使用 execve 的例子:
#include <stdio.h>
#include <unistd.h>
int main() {
char *args[] = {"/bin/ls", "-l", NULL};
execve("/bin/ls", args, NULL);
return 0;
}
在这个例子中,我们使用 execve 来执行 /bin/ls -l,这个程序会列出当前目录下的文件。
exit
exit 系统调用用于结束当前进程。exit 有一个输入参数用于表达退出的状态。
wait
wait 系统调用用于等待一个子进程结束。如果当前没有子进程,wait 会立即返回。如果有子进程结束,wait 会返回这个子进程的 PID。
如果在子进程退出时父进程没有调用 wait,那么子进程会变成僵尸进程,会有一些核心资源无法回收。僵尸进程会占用系统资源,因此我们应该在子进程退出时调用 wait 来回收资源。另一方面,如果父进程先退出了,那么子进程会成为孤儿进程,这时候子进程会被 init 进程接管,init 进程会调用 wait 来回收资源。init 进程一旦退出,就会造成 kernel panic。
下面是一个使用 wait 的例子:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int pid = fork();
if (pid < 0) {
printf("fork failed\n");
} else if (pid == 0) {
printf("I am child process\n");
sleep(1);
} else {
wait(NULL);
printf("I am parent process\n");
}
return 0;
}
在上面的例子中,父进程会等待子进程结束后再输出 I am parent process。
Unix 产生子进程的方式
关于多进程,我们的需求通常是产生一个子进程,而这个子进程通常是和父进程不同的。
利用我们上面介绍的四个系统调用,Unix 中我们通常会使用下面的方法来满足上述需求:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int pid = fork();
if (pid < 0) {
printf("fork failed\n");
} else if (pid == 0) {
// child process
char *args[] = {"/bin/ls", "-l", NULL};
execve("/bin/ls", args, NULL);
} else {
// 父进程
wait(NULL);
}
exit(0);
}
如你所见,我们通常会先使用 fork 产生一个子进程,然后在子进程中使用 exec 来加载一个新的程序。父进程通常会使用 wait 来等待子进程结束。
在这个例子中,父进程会产生一个子进程,然后等待子进程结束。子进程会执行 /bin/ls -l。
Service
Microkernel
Service 是 microkernel 的核心组件之一。我们先来看一下 microkernel 的定义(摘自维基百科):
Microkernel 的设计理念,是将系统服务的实现,与系统的基本操作规则区分开来。它实现的方式,是将核心功能模块化,划分成几个独立的进程,各自运行,这些进程被称为服务(service)。所有的 service,都运行在不同的地址空间。只有需要绝对特权的进程,才能在 S mode 下运行,其余的进程则在 U mode 运行。
这样的设计,使内核中最核心的功能,设计上变的更简单。需要特权的部分,只有基本的线程管理,内存管理和进程间通信等,这个部分,由一个简单的硬件抽象层与关键的系统调用组成。其余的服务进程,则移至用户空间。
让服务各自独立,可以减少系统之间的耦合度,易于实现与调试,也可增进可移植性。它可以避免单一组件失效,而造成整个系统崩溃,内核只需要重启这个组件,不致于影响其他服务器的功能,使系统稳定度增加。同时,操作系统也可以视需要,抽换或新增某些服务进程,使功能更有弹性。
因为所有服务进程都各自在不同地址空间运行,因此在微核心架构下,不能像宏内核一样直接进行函数调用。在微核心架构下,要建立一个进程间通信机制,通过消息传递的机制来让服务进程间相互交换消息,调用彼此的服务,以及完成同步。采用主从式架构,使得它在分布式系统中有特别的优势,因为远程系统与本地进程间,可以采用同一套进程间通信机制。
Overview
在我们的系统中,为了简单起见,我们一共需要实现以下几个 service:
- Scheduler (S mode)
- Drivers (U mode) Undetermined
- File system (U mode)
- Process manager (U mode)
我们可以用一张图来总结上述 services 之间的关系:
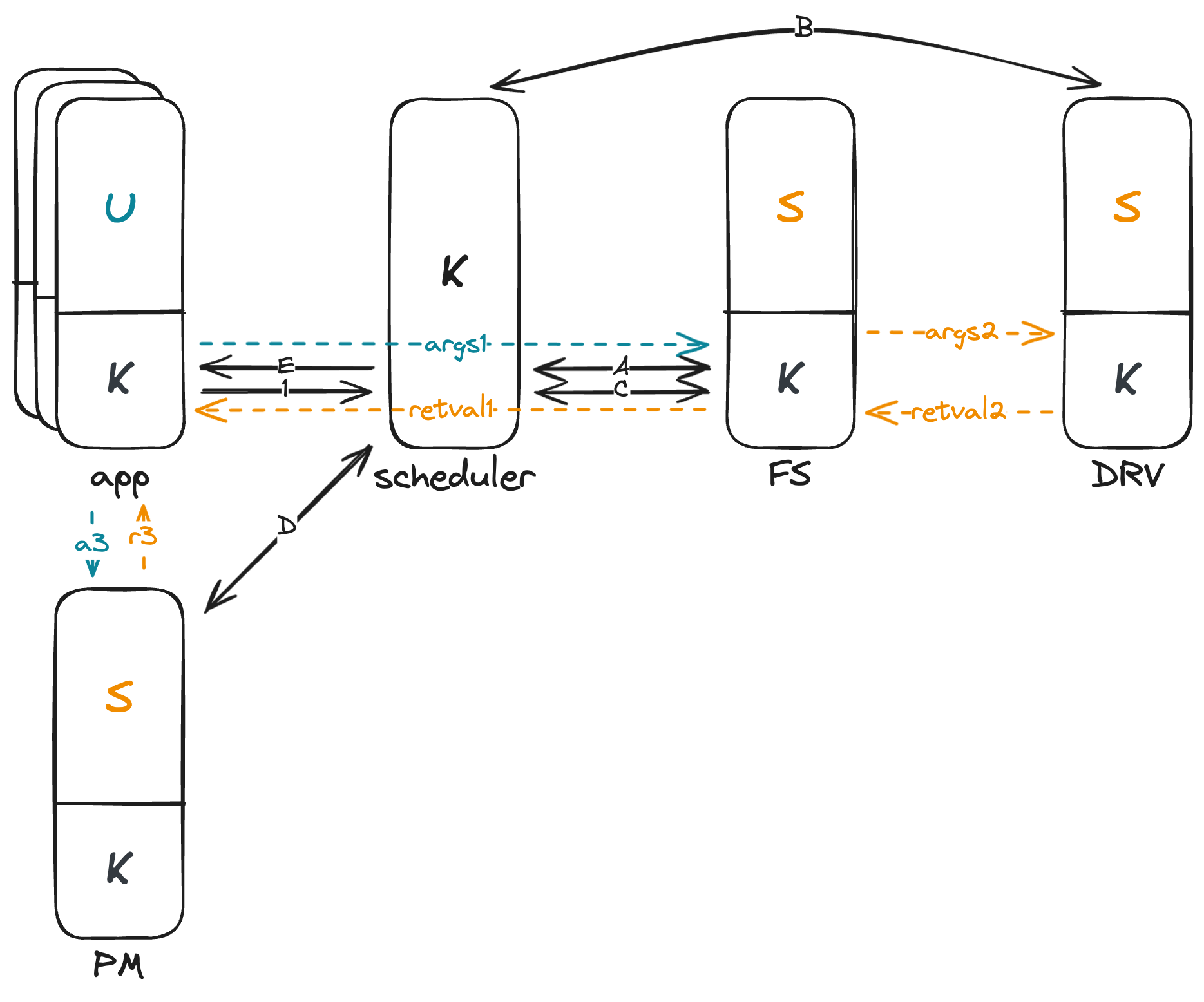
这张图描述了一个用户程序进行 sys_open 的完整流程。
开始于应用程序(App):
- 用户程序发起一个
syscall进入内核态,并传递相关参数如syscall number、path和flags。 - 内核态的
syscall handler根据syscall number调用相应的服务。在本例中,需要获取某个路径(path)下的文件,因此内核线程通过 IPC 请求 文件系统服务(File System Service)。 - 请求发出后,内核线程进入等待状态,并切换到 调度器(Scheduler) 管理。
调度器(Scheduler)过程:
- 调度器根据任务队列和调度算法,选择下一个要执行的服务。此例中,假设它先后选择了 文件系统服务 和 驱动服务(Driver Service)。
在文件系统服务(File System Service):
- 系统从内核线程切换至用户线程(U模式),文件系统服务 尝试根据
path查找文件,并将结果返回给内核线程。 - 文件系统服务 需要访问块设备(block device)以获得数据,因此又通过 IPC 请求 驱动服务。
- 请求完成后,用户线程切换回内核线程,并再次转至 调度器。
再次到调度器(Scheduler):
- 根据当前任务队列,调度器 再次选择下一个要执行的任务。
在驱动服务(Driver Service):
- 驱动服务操作块设备读取数据,完成后将数据返回至 文件系统服务。
- 数据交换完毕后,控制权再次返回 调度器。
返回到文件系统服务:
- 文件系统服务 获取到所需数据,并最终找到文件,将文件信息传递回最初请求的 应用程序 的内核线程。
回到应用程序(App):
- 内核线程收到文件信息,随后联系 进程管理器(Process Manager),以便为文件创建一个新的文件描述符。
在进程管理器(Process Manager):
- 进程管理器 为 应用程序 创建并返回新的文件描述符。
结束于应用程序(App):
- 应用程序 的内核线程接收到文件描述符后,完成整个
sys_open调用,并将控制权返回给用户程序。
通过这一整套流程,可以清楚地看出微内核系统中各个服务的协作方式,以及进程间通信的重要作用。
内核线程
在进入多任务之前,我们始终只有一个内核线程在运行。不过,这样我们就无法很方便地处理多用户进程的情况了。
在多用户进程的情况下,通常每个进程都有一个内核线程与之对应,这样的做法更利于调度。在调度时,我们会先让用户进程进入到内核态,然后再切换到对应的内核线程。
这里还要补充一下,我们之所以说内核线程,而非内核进程,是因为内核线程共享了地址空间。内核线程的地址空间是一样的,而它们的栈是不同的。
内核线程的创建
要创建一个内核线程,我们需要:
- 为内核线程分配一个栈(注意,为了防止爆栈,请不要按照 rCore 上的大小来开栈,通常需要开至少四个页,即至少 16KiB);
- 为内核线程分配一个
Task结构体,用于保存线程的上下文信息。
内核线程的切换
切换线程只需要保存上下文(即所有的寄存器和 pc 寄存器的值)即可。而且,我们注意到,由于函数调用需要遵循 calling convention,因此如果调用函数,这个函数(我们在这里称为 switch)专门用来切换内核进程,我们只需要将所有的 callee-saved 寄存器保存到内存中,然后再从内存恢复即可。关于 pc 寄存器,只要我们将之前调用这个切换内核线程的函数的返回地址恢复到 ra,那么 ret 的时候就会跳转到这个地址。
为了保存这些上下文信息,我们需要传入两个指针分别存放切换前后的线程上下文。
综合上面的分析,我们可以总结出 switch 函数需要做的事情:
- 将 callee-saved 寄存器保存到切换前的线程上下文中;
- 从切换后的线程上下文中恢复 callee-saved 寄存器;
- 返回 (
ret)。
其中,callee-saved 寄存器包括 s0-s11、ra、sp。
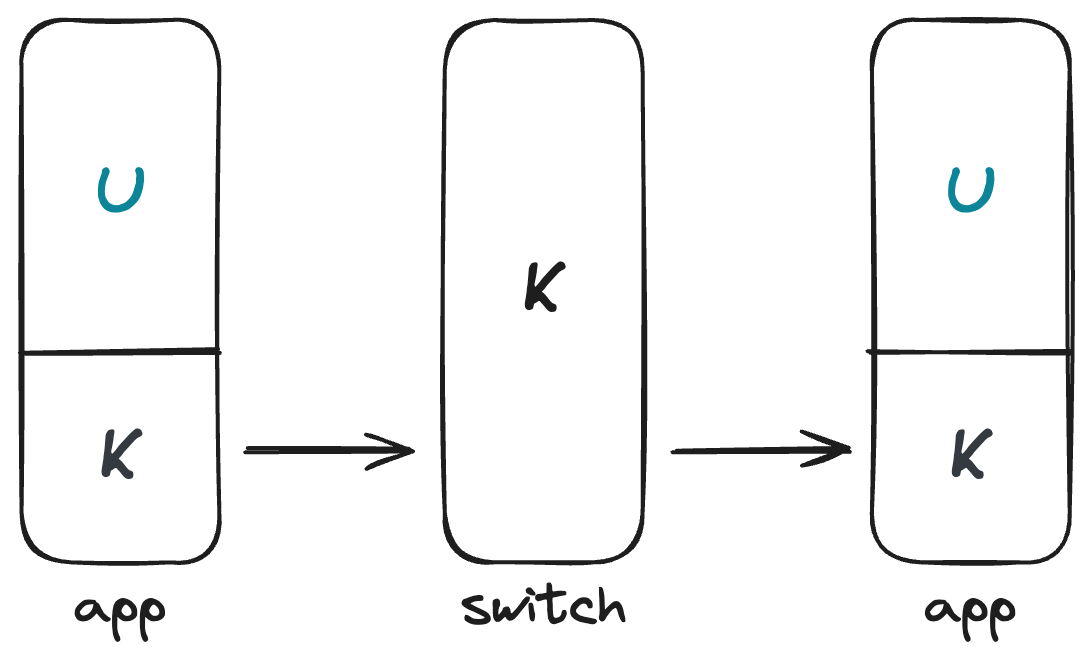
调度器
调度器是一个内核线程,它的主要工作是根据一定的调度算法,选择下一个要执行的内核线程。一个最简单的调度器是循环调度器,它会依次选择下一个线程。一次任务切换如下图所示:
任务
我们调度的最小粒度是任务。任务是一个内核线程的抽象,它包含了线程的上下文信息,以及一些其他信息,比如任务的状态等。以下是一个任务的结构:
struct Task {
context: TaskContext,
state: TaskState,
// ..., other field for scheduling or something else
}进程
进程结构
在微内核设计中,进程(Process)在进程管理器(Process Manager)中进行维护。进程管理器是一个服务,负责创建、销毁和管理进程。它还负责为进程分配资源,例如文件描述符等。
以下是一个进程结构的示例:
struct Process {
pid: usize, // 进程ID,唯一标识一个进程。
vmspace: VmSpace, // 进程的虚拟内存空间
pagetable: VirAddr, // 用于内存管理的页表,必须在内核态中进行分配,因为需要操作包含物理地址的页表
state: ProcessState, // 进程的当前状态(例如 active、dead 等)
parent: Option<Weak<Process>>, // 指向父进程的弱引用
children: Vec<Arc<Process>>, // 包含所有子进程的引用
fdtable: FdTable, // 进程的文件描述符表
}与任务的关系
在切换内核进程中,我们提到了任务。需要明确的是,进程与任务虽有交集,但本质上是两个不同的概念。
进程是资源分配的基本单元,相对独立,并且在操作系统中具有各自的内存和系统资源。它们是系统资源管理和分配的基础,使得多个程序能在多任务操作系统中同时运行而互不干扰。
任务通常指被调度器调度的执行单元。任务包含了一切与执行调度相关的信息。
在进程管理器中维护的进程信息,更多的是一些与调度无关的基础信息,例如文件描述符表、父进程和子进程等。这些信息在调度中不需要,所以并不需要将它们保存在内核的任务结构中。相应地,它们被保存在用户态的进程管理器里。
所以,在调度器中,我们只需要访问任务结构,而不需要访问进程结构。进程结构只在进程管理器中使用。
页表
需要注意的是,进程的页表是在内核态中分配的。这是因为页表中包含了物理地址,而用户态无法直接访问物理地址(除非配置 identical mapping)。因此,页表的分配必须在内核态中进行。
文件系统
人们注意到,仅有内存作为储存信息的媒介是不够的。因为当内存发生断电时,所有信息都会丢失。因此我们需要一种持久化的储存媒介。持久化的储存媒介种类很多,比如固态硬盘、机械硬盘、光盘等等。在操作系统中,我们统一将这些媒介抽象为块设备。
从用户的角度来看,用户希望能够使用多个文件,这样可以更方便地区分不同的信息。这意味着我们需要制定一个格式,用于在块设备上确定每个文件中的数据所在的位置。这个格式就是文件系统。
尽管文件系统是一个复杂的子系统,但是通过模块化设计,我们可以将文件系统分为三个层次,每个层次负责不同的功能。这样可以使得文件系统的设计更加清晰。三个层次分别为:
- 块设备驱动:负责与块设备进行交互,读写数据,这里面有很多跟硬件交互的逻辑。
- 文件系统驱动:负责将文件系统的操作转换为块设备的操作,由于已经有了块设备抽象,这个部分只需要关注核心逻辑即可。
- 系统调用:发生系统调用时,用户程序的内核部分会调用文件系统驱动(这里面可能还会有一些逻辑上的转换,如文件描述符到对应 inode 的转换)。
文件系统接口介绍及要求
这里我们将从用户的角度,介绍文件系统对用户的接口。
文件系统接口要求
我们要求文件系统需要支持以下功能(你可以用多个系统调用来实现,如用 seek + read 来实现读,但不接受过于复杂的实现逻辑):
- 新建目录及文件:可在任何位置新建目录及文件
- 删除目录及文件:可删除除根目录以外的任何目录及文件
- 修改目录名及文件名:可修改目录及文件的名字
- 读取目录及文件:可读取特定位置的特定长度的内容
- 写入目录及文件:可写入特定位置的特定长度的内容
- 移动目录及文件:可移动目录及文件到另一个位置
我们建议实现以下功能:
- 文件和目录的权限控制
- 文件和目录的时间戳
文件系统接口介绍
这里我们按照 Linux 的文件系统接口来介绍文件系统的接口,你不一定要严格按照这里的接口来实现。
索引节点 Index Node (inode)
在类 Unix 操作系统中,每个文件都会有一个 inode 与之对应,inode 储存了文件的元数据信息,如文件大小、文件权限、文件所有者等。当我们需要访问文件时,我们会先通过文件名找到 inode,然后通过 inode 找到文件的数据块。通过文件名找到 inode 的过程由文件系统的设计决定。
在类 Unix 操作系统中,文件名不是文件的属性,其只用于索引。这为硬链接提供了便利,只要两个文件指向的 inode 相同,那么这两个文件就是硬链接。为了方便删除文件,inode 中会记录文件的硬链接数,当硬链接数为 0 时,文件会被删除。
目录索引
在类 Unix 操作系统中,目录的作用是一层层地找到文件的 inode。目录也是一个文件,其记录了当前目录的文件和子目录的 inode,以及自己和父目录的 inode。对于根目录,其父目录的 inode 为自己的 inode。
因此,找文件的过程就是从根目录开始(根目录的 inode 会在文件系统驱动初始化的时候找到),找到下一层的目录 inode,进而找到下一层目录的内容,这样逐层找到文件的 inode。
文件描述符 File Descriptor (fd)
文件描述符 (File Descriptor, fd) 是一个整数,其用于标识一个文件。当我们打开一个文件时,文件系统会返回一个文件描述符,之后我们可以通过这个文件描述符来操作文件。文件描述符是进程的属性,因此不同进程的文件描述符可以指向同一个文件。
在 task_struct 中,我们会记录文件描述符表,其记录了文件描述符和 inode 的对应关系。
实际上,在 Linux 中,文件描述符还可以只带其他的东西,如网络连接、管道、外部设备等。
系统调用
如果要使用文件,需要先打开文件。对应的系统调用有 open(其实还有其他接口,但是我们只需要管 open 即可)。open 会返回一个文件描述符,之后我们可以通过这个文件描述符来操作文件。open 还可以通过 flags 来指定打开文件的方式,如只读、只写、读写、创建文件等。具体请看 manpage。
对于文件读写,在 Linux 中有两套方法,一套是先 lseek 到对应的位置,再 read 或 write,另一套是直接 pread 或 pwrite。pread 和 pwrite 会直接指定初始的位置,而 read 和 write 不会。
使用完文件后,需要关闭文件。对应的系统调用是 close。close 会释放文件描述符,之后这个文件描述符就不再指代该文件了。
文件系统服务
文件系统服务负责处理所有与文件系统相关的操作,因此内核和用户空间的程序都需要通过文件系统服务来访问文件系统。
文件系统会向上暴露一些文件接口,其自身会维护一些缓存数据以及文件系统的元数据,并且在必要时向下调用块设备服务来读写数据。
关于向上的接口,你可以采取任何的实现,只要符合前面要求的应用接口即可。但是,我们还是希望大家使用一些方便的接口,便于其他内核线程使用。
通常情况下,文件系统模块还会记录一些元数据,以及一部分缓存数据,以便提高文件系统的性能。缓存包括但不限于文件数据、目录数据、文件元数据等。在 Linux 中,缓存的文件数据会被称为 page cache。Page cache 会在内存中缓存文件数据,对 mmap 特别有用。
文件系统设计
文件系统的设计与需求有关,我们这里对性能和效率都没有什么要求,一切以方便实现和调试为主。
所有的文件系统都需要有一个超级块 (super block),用于持久地保存文件系统的元数据,如文件系统块的大小等。超级块通常会被放在文件系统的第一个块,以便文件系统驱动在初始化时读取。
此外,文件系统基本都有索引部分和数据部分,用于管理文件的数据以及文件系统空闲块。
关于具体的实现,可以参考rcore 的设计。为了方便调试,除了为你的内核提供支持外,你最好还要在实现一个制作镜像或编辑镜像的工具(可以共用一套库)。